Ce post (comme les précédents) est écrit sans IA, Il s'inspire des retours d’expérience fidèles et personnels.
L’histoire de l’informatique a quelque chose d’assez fascinant : les technologies changent, les architectures évoluent au gré des besoins… et surtout des buzzwords qui se succèdent à grande vitesse.
Et pourtant, certaines erreurs semblent bénéficier d’une remarquable forme d’immortalité. L’IA n’échappe probablement pas à cette règle.
Depuis des mois, les démonstrations IA se multiplient partout. Les agents conversationnels apparaissent dans tous les domaines. Les workflows “augmentés par IA” deviennent omniprésents. Les POCs s’enchaînent avec cette sensation collective que nous sommes en train de vivre une rupture technologique majeure et il serait absurde de nier que cette rupture existe réellement.
Mais il serait tout aussi dangereux de croire que le simple changement de technologie suffit à faire disparaître les vieux problèmes structurels. Car en regardant certaines architectures émerger aujourd’hui, un étrange sentiment de déjà-vu commence parfois à apparaître.
Une impression qui rappelle fortement une autre époque : celle du RPA introduit dans les organisations.
Une technologie envers laquelle j’ai toujours été relativement circonspect. Le RPA était poussé avec un véritable engouement et accueilli comme le messie de la productivité augmentée. L’enthousiasme était immense et l’automatisation promettait de révolutionner la productivité des équipes. Les démonstrateurs impressionnaient et les ROIs rapides devenaient les nouveaux arguments magiques des directions avec des robots capables de reproduire automatiquement des actions humaines sur une interface. L'approche devenait soudainement la réponse à une multitude de problèmes métier.
Et pendant quelque temps, cela semblait fonctionner et les premiers retours d’expérience se sont alors installés :
“Le RPA doit être rapide à implémenter.”, “Le ROI doit être immédiat.”, “Enfin, on peut automatiser toute la facturation.”, “On peut automatiser le traitement complet des demandes.” et surtout “On peut éviter de modifier le SI existant.”
C’est probablement cette dernière phrase qui était la plus importante… ou plutôt la plus inquiétante.
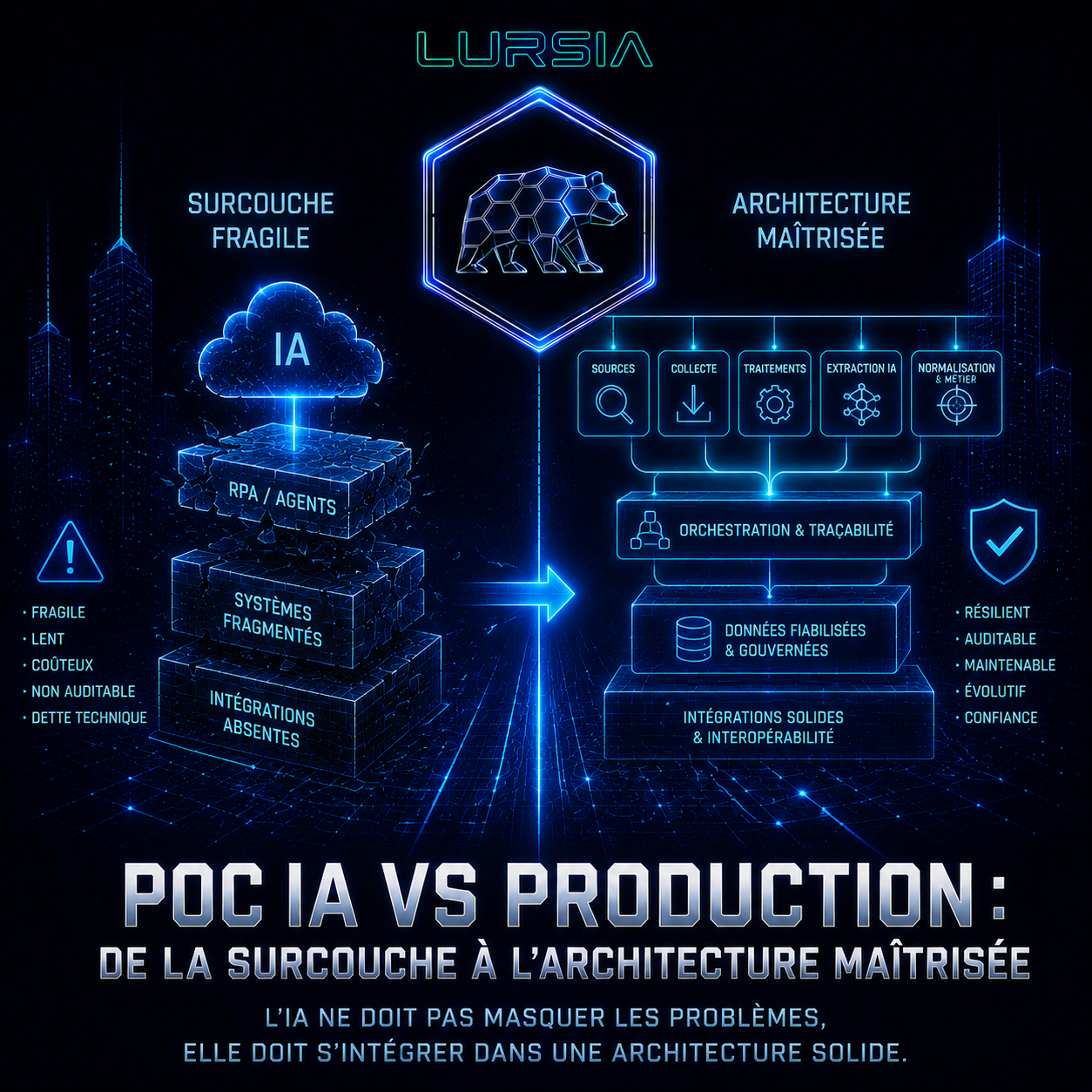
Car derrière la beauté théorique de la technologie se cachait souvent une autre réalité : le RPA servait principalement de surcouche destinée à compenser l’absence de véritables protocoles d’intégration entre systèmes.
Autrement dit, au lieu de résoudre certains problèmes structurels du système d’information, on ajoutait une couche supplémentaire capable d’imiter artificiellement un comportement humain au-dessus d’architectures qui restaient elles-mêmes profondément fragmentées et peu interopérables.
Et évidemment, cela donnait l’impression de fonctionner. Du moins… jusqu’à un certain point.
Parce qu’un robot qui clique sur des boutons reste fondamentalement moins robuste qu’une intégration pensée nativement entre systèmes : plus lent, plus fragile, plus difficile à maintenir, dépendant des évolutions d’interfaces… donc plus coûteux dans le temps.
Chaque changement d’écran devenait potentiellement un incident. Chaque évolution du SI faisait apparaître de nouvelles dépendances invisibles. La dette technique ne disparaissait pas mais elle changeait simplement de forme.
Et c’est probablement là que le parallèle avec certaines trajectoires actuelles autour de l’IA devient intéressant. Car nous observons aujourd’hui un phénomène relativement proche. Face aux limites des systèmes existants, beaucoup d’organisations ajoutent désormais des couches IA capables d’interpréter des données incohérentes, reconnecter artificiellement des flux, reformuler des contenus, combler des vides fonctionnels ou masquer temporairement certaines faiblesses structurelles du SI. Et là aussi les démonstrations fonctionnent souvent très bien.
Mais une question mérite probablement d’être posée honnêtement :
Sommes-nous en train de résoudre durablement les problèmes… ou simplement de construire une nouvelle surcouche au-dessus d’architectures qui restent elles-mêmes peu maîtrisées, mal interfacées et mal coordonnées ?
L’IA possède cette capacité extrêmement séduisante de masquer temporairement une partie de la complexité. Un agent peut interpréter (parfois mal) des données incohérentes, réconcilier des terminologies différentes, naviguer entre plusieurs outils grâce aux nouveaux protocoles, ou donner l’impression de compenser certaines faiblesses de structuration.
Tout cela crée artificiellement de la continuité et de la fluidité là où le système n’en possède pas réellement.
Le risque apparaît lorsque ces couches IA commencent progressivement à devenir elles-mêmes des dépendances structurelles du SI et c’est précisément ce que l’on commence déjà à observer.
La logique métier migre lentement dans des chaînes de prompts non versionnées, souvent fortement couplées aux agents utilisés car les décisions prises deviennent alors plus difficiles à auditer. Les mécanismes de raisonnement deviennent alors moins explicitables. Au final, Les workflows agentiques finissent parfois par devenir plus complexes que les systèmes qu’ils étaient censés simplifier. Et à ce moment-là, une nouvelle dette apparaît.
Une dette probablement encore plus difficile à gouverner, car elle touche directement à la compréhension des décisions, à l’auditabilité, à la traçabilité, à la responsabilité… et finalement à la confiance globale de l’organisation envers ses propres systèmes.
Or cette confiance reste aujourd’hui l’une des principales causes de rejet dans les organisations.
Le problème n’est donc pas l’IA elle-même. Le problème apparaît lorsque l’IA devient un substitut permanent à des problèmes d’architecture qui auraient nécessité une réflexion plus profonde sur les modèles de données, les protocoles d’échange, la sémantique métier, la gouvernance ou la trajectoire globale du SI. Car ne vous leurez pas : Un système d’information finit toujours par présenter la facture des raccourcis qu’on lui impose.
C’est précisément cette réflexion qui influence fortement certaines décisions d’architecture que je prends régulièrement.
A titre d'exemple, dans le cadre de la conception d’une plateforme d’analyse industrielle intelligente, une question très concrète est rapidement apparue : Comment construire une chaîne capable de collecter, consolider et fiabiliser des données provenant d’un environnement fondamentalement chaotique ?
Dans notre cas, les données provenaient de multiples sources : fabricants, distributeurs, data providers selon de multiples canaux: APIs, scraping web, mails, bases documentaires. Elles prenaient par ailleurs des formes extrêmement variées : PDF, JSON, photos, tableaux, courbes, schémas techniques, données réglementaires ou supply-chain et présentaient toutes des niveaux de qualité très hétérogènes.
La tentation classique aurait consisté à construire un “super agent” capable de tout faire : chercher les données, naviguer, comprendre les documents, extraire les informations, interpréter les résultats et produire directement une fiche métier finale.
Sur le papier, la démonstration aurait probablement été spectaculaire mais En réalité, cela aurait surtout produit un système extrêmement difficile à expliquer, auditer et maintenir.
C'est pour cela qu'une autre direction a été prise: Plutôt que de considérer l’IA comme le cerveau unique du système, le choix a été de construire une véritable chaîne industrielle autour d’elle. L’idée n’était pas de créer un agent capable de tout faire, mais au contraire de séparer clairement les responsabilités et surtout déléguer à l'IA uniquement ce pour quoi elle est performante. La recherche des sources est isolée de la collecte elle-même. La sélection des liens utiles possède sa propre logique. Le découpage des contenus et la détection des zones d’intérêt interviennent indépendamment des traitements d’extraction par agent spécialisé. Puis viennent ensuite les étapes de normalisation, de nettoyage, de restructuration et de rattachement métier.
Cela paraît probablement moins “magique” dans une démonstration. En revanche, cela change complètement la résilience du système, permet de tester chaque brique indépendamment et le faire évoluer de manière modulaire.
Lorsqu’une extraction produit une incohérence, nous sommes capables d’identifier précisément l’origine du problème : la source utilisée, le fragment analysé, le modèle sollicité, la version exacte du workflow ou encore la phase de traitement concernée. Et surtout, nous pouvons relancer uniquement une étape spécifique sans avoir à rejouer toute la chaîne de traitement.
Et ce point devient absolument fondamental à l’échelle industrielle.
Parce qu’un POC accepte facilement l’approximation mais la production, du fait du volume et de la diversité des cas rencontrés, beaucoup moins.
Par ailleurs, les données récupérées sont sauvegardées en brut, sans modification, et un lineage complet a été mis en place sur toute la chaîne de propagation. Certaines étapes utilisent effectivement des agents alors que d’autres reposent simplement sur des algorithmes classiques, parfois plus performants et surtout plus facilement auditables. L’architecture reste donc volontairement hybride. L’IA n’est utilisée que lorsqu’elle apporte un gain réel.
Et surtout une sortie IA ne doit jamais être considérée comme une donnée métier finale. Prenons un exemple simple dans un système de gestion de produits chargé d'extraire des dates sur ces produits telles que des date de fabrication, date d'obsolescence, date de remplacement, etc. Un agent peut parfaitement extraire plusieurs dates correspondant à ce produit depuis différentes sources d'information mais les sources d'erreurs peuvent être importantes car il peut récupérer des documents correspondant à des références produit proches mais par exactement celle voulues, Il peut détecter des informations contradictoires (et ne pas le remonter!), il peut aussi extraire une information qui ne correspond pas à ce qu'il doit rechercher en une erreur d'interprétation. La chaine de traitement apportant une vraie fiabilité devient alors beaucoup plus complexe qu'une démonstration basée sur un simple agent. Si la démo basée sur un simple agent est facile à mettre en place et paraît plus impressionnante: “Le modèle a trouvé immédiatement des informations!” - Oui mais avec quel taux de succès?
Dans l'autre système Il faut normaliser, supprimer les redondances, comparer les résultats entre sources, pondérer les niveaux de confiance selon les sources, lever les ambiguïtés, détecter les erreurs d’interprétation puis seulement en bout de chaine rattacher l’ensemble à une logique métier exploitable.
Autrement dit : L’IA alimente une chaîne de production en s'y intégrant mais elle ne remplace pas la chaîne elle-même et ce qui en fait son intelligence métier.
Un autre apprentissage important concerne la mutualisation: dans beaucoup de POCs IA, chaque demande utilisateur déclenche un traitement complet. Cela fonctionne très bien… jusqu’au moment où les coûts explosent et où les traitements deviennent redondants. Il semble donc logique d'introduire une logique différente : dissocier la demande d'un utilisateur de la production technique réelle. Ainsi, si plusieurs utilisateurs demandent la même référence, il n’est pas nécessaire de rejouer toute la chaîne et les traitements associés. Le système réutilise une production existante lorsque cela est pertinent. Ici pas d'IA, juste du bon sens pour réduire les coûts. Et si cela paraît évident après coup c’est malheureusement le genre de mécanisme que les démonstrateurs n'intègrent pas (tout comme le produit final!) parce qu’ils ne vivent pas encore réellement les contraintes de production.
C’est probablement là que se situe le véritable passage du POC à l’industrialisation c'est à dire Le moment où l’on cesse de construire une démonstration impressionnante pour commencer à construire un système capable de survivre à la volumétrie, au temps, aux évolutions, aux incidents, aux audits, aux coûts, et surtout aux équipes qui devront non seulement maintenir tout cela dans cinq ans mais aussi aux utilisateurs qui l’utiliseront tous les jours. Ces utilisateurs devront faire confiance au système et il n'y a pas de doute que des utilisateurs dubitatifs envers l'IA n'hésiteront pas à lui faire une mauvaise publicité dès que l'occasion se présentera!
Au fond, un système IA réellement mature n’est pas celui qui semble le plus intelligent pendant une démonstration. C’est celui qui reste compréhensible, gouvernable, maintenable une fois la démonstration terminée et fourni un niveau de robustesse attendu par le métier